

この記事でわかること
・ RAGの仕組み
・ RAGと生成AI・AIエージェントの違い
・ NotebookLMの始め方
「AIを業務に活用したい。でも、安全性に不安がある。」
そんな企業の悩みに応える選択肢として、いま注目されているのが「RAG(検索拡張生成)」です。
RAGとは、AIが社内資料などの外部情報を参照して回答する仕組みのこと。
生成AIの弱点であるハルシネーションや情報漏洩リスクを抑え、企業でも安心して活用しやすくする技術です。
このRAGの仕組みを、専門知識がなくても手軽に体感できる代表的なツールが、GoogleのNotebookLMです。
本記事では、RAGの基本的な仕組みと生成AIとの違いを整理しながら、NotebookLMを使って安全に社内AIを活用する方法をわかりやすく解説します。
なぜ生成AIの企業利用には不安が残るのか
生成AIは万能に見えますが、企業の業務でそのまま使うには「3つの構造的な壁」が存在します。
この壁こそが、多くの企業がAI導入に二の足を踏む原因となっています。
では、その理由を具体的に見ていきましょう。
ハルシネーション(誤情報生成)のリスク
通常の生成AIは、インターネット上の膨大なデータを事前学習しています。
つまり、世界中の教科書、辞書、ウェブサイトからの情報をインプットした「膨大な知識の集合体」と言えます。
利用者が質問を投げかけると、AIはその膨大な知識の中から文脈に沿って「もっともらしい言葉」を確率的に予測し、流暢な文章を生成します。
しかし、生成AIには「事実か否か」を判断する能力はありません。
そのため、学習データにないことや不確実な情報であっても、確率的にそれらしい文章をつなぎ合わせて架空の事実や誤った情報を生成してしまうことがあります。
これを専門用語で「ハルシネーション」といいます。
企業の実務において、根拠のない「もっともらしい誤情報」が生成されるリスクは、業務利用における最大の懸念点となります。
企業の個別事情(社内データ)を理解できない
生成AIが学習しているのは、あくまでインターネット上に公開された「一般的な情報」です。
企業の内部情報である就業規則、顧客リスト、プロジェクトの経緯などは、AIの学習データに含まれていません。
そのため「当社の経費精算の締日」「A社との契約条件」といった、実務で本当に必要な質問に対して、AIは正解を持ち合わせていません。
結果として『一般的な経費精算のプロセス』や『標準的な契約条項』といった一般論しか返ってこないので、個別の業務課題を解決するには至らないのです。
業務効率化を目指すうえで、この「自社の情報を理解していない」という点は、実務利用における大きな障壁となります。
情報漏洩リスクと社内データ入力の課題
「ならば、社内データをAIに入力して教えてあげればいいのでは?」
そう考えた方もいらっしゃるかもしれません。
しかし一般的な生成AIサービスでは、入力したデータの取り扱いについて慎重に考える必要があります。
サービスや利用プランによっては、入力内容がAIの改善や再学習に使われる可能性があるためです。
もちろん、入力した情報がそのまま他社への回答として表示されるというようなリスクは決して高いものではありません。
ですが、社外秘の議事録や顧客情報など、取り扱いに注意が必要なデータについては「万が一のリスクも考慮すべき」というのが多くの企業の共通認識でしょう。
現在の大手AIサービスには、個人情報などを保護するためのフィルタリングや制御の仕組みが用意されています。
それでも企業のセキュリティポリシー上、機密情報をそのまま入力することが難しいケースは少なくありません。
実際に多くの企業がChatGPTなどの生成AI利用を「禁止」または「一部制限」している背景には、このような意図しない情報の取り扱いに対する懸念があるのです。
RAGと生成AIとの違い
これらの課題や弱点を解決し、AIを『安全なパートナー』に変えるために考案されたのが、外部知識を参照するRAG(Retrieval Augmented Generation/検索拡張生成)という技術です。
RAG(検索拡張生成)の仕組み
RAGの仕組み自体は非常に合理的。
簡潔にまとめると、「AIに信頼できる外部資料(ナレッジベース)を参照させること」です。
具体的には、AIが回答を生成する前に指定された社内データや信頼できる外部ナレッジ(マニュアル、議事録など)を検索し、その内容を基に回答を作成する技術です。
AI自身の学習データ(記憶)に依存せず、常に最新かつ正確な参照元の情報を利用できる点が最大の特徴です。
RAGを組み込んだAIは、質問に対して以下の3ステップで処理を行います。
ユーザーの質問に関連する社内マニュアル、議事録、顧客データなどを、データベースの中から瞬時に検索・抽出します。
検索で得られたデータを、質問文とセットにしてAIに提示します。
ここで「この資料の内容を正解として扱う」という指示をシステム的に加えます。
AIは自身の記憶ではなく、渡されたデータ(根拠)に基づいて回答を構築します。
これにより事実に基づいた正確なアウトプットが可能になります。
つまりRAGを導入することで、AIは「不確実な学習済みデータ(暗記)」に依存せず、「指定された資料(事実)」に基づいて回答することが可能になります。
これにより、AIの創造性と社内データの正確性を両立させることができるのです。
通常の生成AIとRAGの違い
これらを表にまとめると、以下のようになります。
| 項目 | 通常の生成AI | RAGを使ったAI |
|---|---|---|
| 役割・特徴 | 豊富な知識から文章を生成する (創造的だが不正確なことも) | 根拠資料に基づいて回答する (事実重視で正確) |
| 情報源 | 過去の学習データ | 指定した最新資料や 社内データベース |
| 社内ルール | 回答不可 | 正確に回答可能 |
| 情報の正確性 | ハルシネーション(誤回答)の リスクあり | 参照元に基づくため ハルシネーションを極小化 |
| 適した業務 | アイデア出し、翻訳、 要約、創作 | 社内規定・マニュアル検索、 エビデンス確認 |
企業の実務においてAIに信頼性を求めるのであれば、「社内の資料を参照し、それに基づいて正確に回答させる」というアプローチが不可欠です。
これがRAGの本質であり、多くの企業が業務利用のスタンダードとして導入を進めている理由です。
RAGとAIエージェントの違い
最近よく耳にする「AIエージェント」と「RAG」は、似ているようで役割が明確に異なります。
RAGが正しい情報を「調べる」ことに特化した検索係だとすれば、AIエージェントはその情報を元にさらに「行動(アクション)」まで行う実行係です。
たとえば、「A社の請求書の締め日は?」と聞かれたとき、マニュアルを参照して「月末です」と正確に答えるのがRAGの仕事です。
そこから一歩進んで、「では、その締め日に合わせて請求書を作成し、メールで送っておきましょうか?」と自律的に提案・実行できるのがAIエージェントです。
夢のような技術ですが、エージェントを使いこなすには、まず「AIに正しい知識(社内データ・コンテキスト)を参照させる」というRAGの土台が不可欠です。
正しい情報源を持たないエージェントは、間違った情報を元に勝手な行動をしてしまうリスクがあるからです。
つまり、RAGで自社の「脳(ナレッジベース)」を構築することこそが、将来的なAIエージェント活用、ひいては業務の完全自動化への最短ルートになる可能性が高いのです。



企業にとってRAGがもたらすメリット
では社内データをAIに連携させることで、具体的にどのような業務改善が見込めるのでしょうか。
RAG導入の主なメリットは以下の3点です。
1. ハルシネーションリスクの低減
RAGは原則としてアップロードされた資料(ソース)に基づいて回答を生成します。
学習データの記憶をつなぎ合わせて勝手な創作をするのではなく、資料に書かれていないことは「書かれていません」と明確に回答します。
これにより、もっともらしい嘘(ハルシネーション)を極小化し、コンプライアンスを遵守した運用が可能になります。
2. 埋もれた社内ナレッジの資産化・活用
どの会社にも、作成されたものの活用されていないマニュアルや、クラウドなどに散逸している議事録などがあるものです。
これらをRAGに取り込むだけで、必要な時に即座に・正確に情報を引き出せるナレッジベースへと資産価値を変えることができます。
ドキュメントの検索に費やしていた膨大な工数を削減できるだけでなく、「ベテラン社員に聞かないと分からない」といった属人的な問い合わせ対応の負担も大幅に軽減されます。
社内Wikiやファイルサーバーよりも、圧倒的に使えるナレッジ共有システムとなる可能性を秘めています。
3. 専門知識不要で導入できるスモールスタート性
企業独自のRAGシステムを構築しようとすると、データベースの知識やPythonなどのプログラミング技術、さらにはサーバーコストが必須です。
しかし、これからご紹介するクラウド型のRAGであれば、ブラウザベースで「現場担当者主導」での導入・検証が可能なのです。
情報システム部門の大掛かりなリソースを割くことなく、まずは身近な業務(例:部署内のQ&A対応)からスモールスタートで始め、その有用性を検証できること。
テクノロジーの急激な進化による変化の激しい現代のビジネスにおいて、この「機動力」は極めて強力な武器となります。
NotebookLMで体感するRAGの仕組み
RAGは企業で生成AIを活用するうえで非常に有効な考え方ですが、RAGを実現するためにはシステム構築や環境整備に多くのコストや時間がかかる点が、大きなハードルとなっていました。
こうした課題に対して現実的な解決策のひとつとして登場したのが、Googleが提供するNotebookLM です。
NotebookLMは、大がかりなシステム構築を行わずにRAGを利用できる選択肢のひとつです。
NotebookLMが選ばれる理由
仮にRAGを自社で実装する場合は、検索の仕組みづくりやデータの扱い方、回答精度の調整などの専門的な検討が必要になります。
その点、クラウドサービスであるNotebookLMではこうした技術的な部分を意識する必要がありません。
利用者は「どの資料をもとに、何を知りたいのか」という業務側の視点に集中することができます。
NotebookLMの使い方は非常にシンプル。
新しいノートブックを作成し、社内マニュアルや議事録、参考にしたいWebページなどの資料を追加するだけで、準備は完了します。
チャット欄から質問を入力すれば、アップロードした資料の内容をもとにした回答が返ってくる仕組みです。
一般的な生成AIのように幅広い知識から推測するのではなく、あくまで「指定した資料の範囲内」で回答を返します。
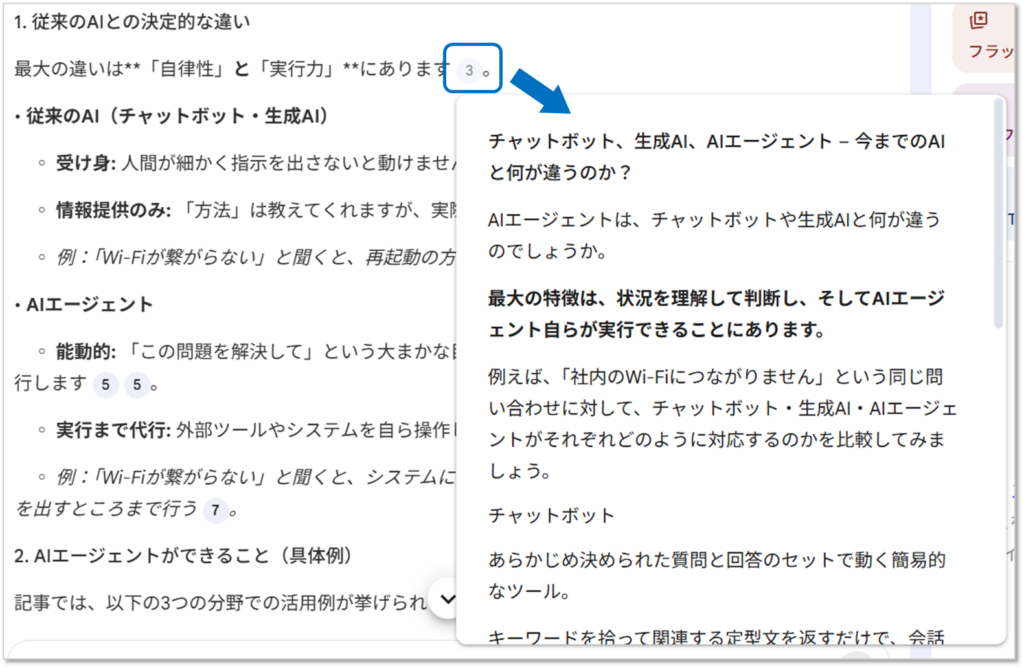
NotebookLMの最大の特徴は、回答の根拠が「ソースガイド(引用元)」として可視化される点です。
回答の横に表示された番号をクリックすると、参照元のPDFやドキュメントの該当箇所が瞬時にハイライト表示されます。
「AIが言っていること」を鵜呑みにせず、「原文にどう書かれているか」をその場ですぐに裏取りできる。
この検証のしやすさこそが、他の生成AIにはないNotebookLMならではの強みであり、業務で利用する上での安心感に直結します。
中小企業こそRAGから始めるべき理由
AI導入は大企業だけの話だと思われがちですが、実はリソースの限られた中小企業こそ、RAG導入の恩恵を最大化できる土壌があります。
その理由をみていきましょう。
業務の属人化解消と標準化
中小企業では、特定のベテラン社員に業務知識やノウハウが偏る「属人化」が深刻な課題となりがちです。
RAGは各業務担当者が持つ個人的なメモ、過去のメール、作成資料などをAIに読み込ませて共有知化することで、個人の記憶に依存しない組織的な業務体制を構築できます。
これは人材不足や退職に伴う引き継ぎリスクを解消し、業務品質を標準化するための極めて有効な手段となります。
「AIへの丸投げ」ではない、根拠に基づく運用
RAGはAIに判断させるのではなく、「人間が作った正しい資料を、AIに素早く探させる」仕組みです。
主役はあくまで「社内の正しい情報」であり、AIはその情報を「高速に検索・要約して提示する優秀なアシスタント」としての役割に徹します。
AIに意思決定を委ねるのではなく、「人間が正しい判断をするための材料を、AIに集めさせる」という運用設計です。
これならば、ブラックボックスな判断を任せる不安なく、既存の業務プロセスにスムーズに組み込むことが可能です。
実践ガイド:NotebookLMの始め方
RAGの有用性を正確に評価するためには、実際に自社のデータを用いて検証を行うことが最も確実な手段です。
利用環境の確認から実務での活用を開始するまでの具体的な手順について解説します。
プランとセキュリティの確認
企業でGoogle Workspace(Business Standard以上)を利用している場合、NotebookLMは既存のプラン内で追加料金なしで利用可能です。
「Gemini for Google Workspace」などの有料アドオンを個別に契約する必要はありません。
さらに重要なのが、企業アカウントで利用する場合は「入力データはAIの学習に使われない」というデータ保護規定が適用される点です。
つまり、追加コストゼロでセキュリティが担保されたRAG環境が手に入ることになります。
(組織の設定によっては、利用に管理者の承認が必要な場合があります)
個人で「Gemini Advanced」を契約している場合も、上位版「NotebookLM Plus」が自動適用されます。
利用手順
では、実際にNotebookLMを操作してみましょう。
ここではGWSアカウントを使って、web版のNotebookLMを操作する手順をご紹介します。
STEP 1:NotebookLMにアクセスする
NotebookLM公式サイト にアクセスし、「NotebookLMを試す」をクリックします。
必要があればアプリをダウンロードしてみましょう。
Gmailでのログインを求められたら、GWSのアカウントでログインします。
ログインが成功すると、NotebookLMのダッシュボードが表示されます。
STEP 2:データソースとなる資料を追加する
データの登録方法は2つ。
新規作成する方法と、サンプル(テンプレート)を試す方法です。
今回は新規で作っていきたいため、「ノートブックを新規作成」をクリックして進みましょう。
新規作成画面で、ソースとなる情報の登録を行ってきます。
中央の「ソースを追加して始める」のエリアに、ファイルをドラックすることでアップロードできます。
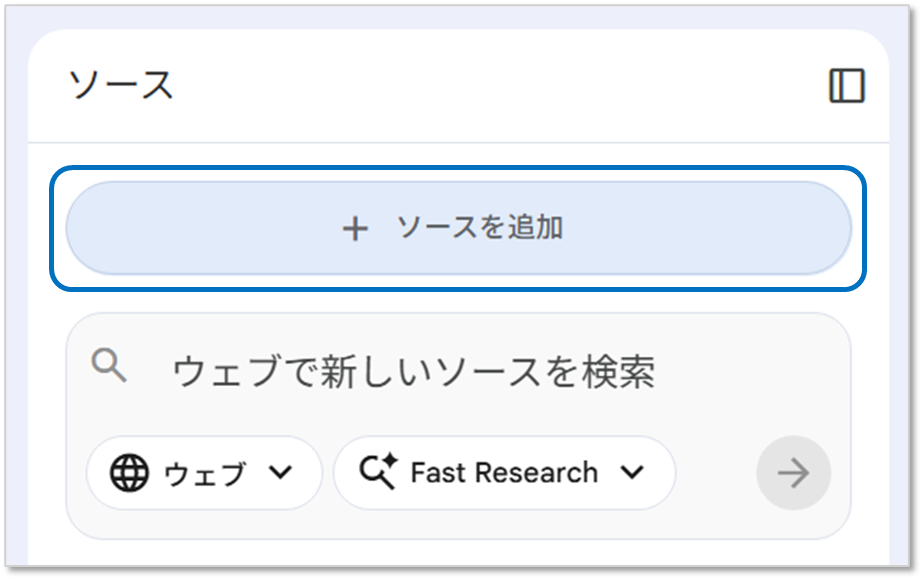
本記事では、サンプルとして当サイトの情報を登録してみます。
URLを登録したいので、左エリアの「ソースを追加」をクリックします。
「ウェブ」になっていることを確認し、NotebookLMに登録したいURLを設定していきます。
ウェブ以外にも、Googleドライブ内のドキュメントが指定可能です。
記事をいくつかピックアップして登録してみます。
URLを入力したら、矢印マーク(→)を選択して登録していきます。
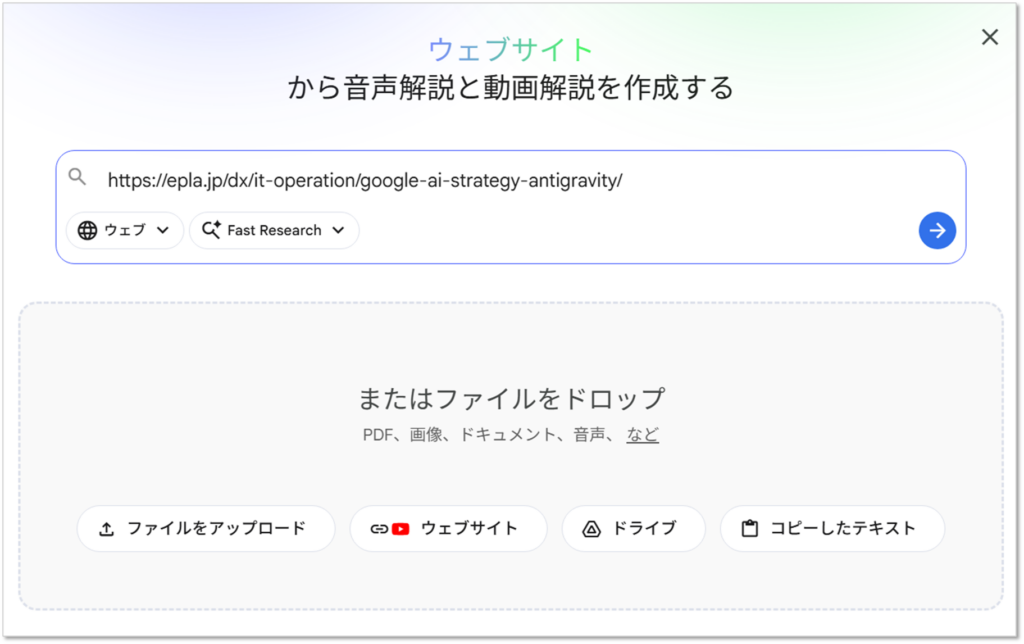
登録がされたデータソースが、左側のエリアに表示されました。
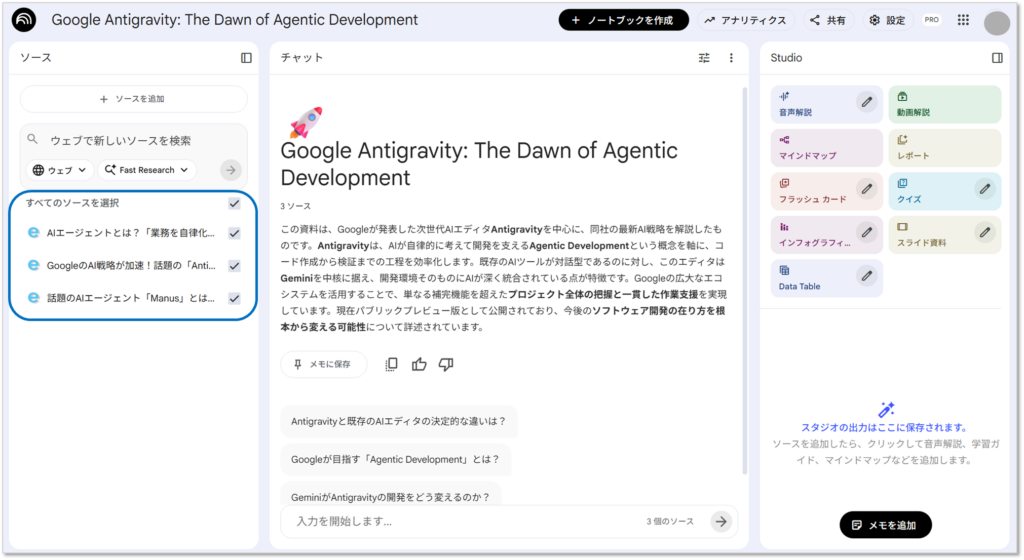
ファイルとして登録可能
・PDFファイル(.pdf)
・テキストファイル(.txt / .md)
・Wordファイル(.docx / .doc)
・画像ファイル(.png / .jpeg / .jpg / .webp など)
・音声ファイル(.mp3 / .wav など)
URLとして登録可能
・WebページのURL
・YouTube(公開)
・Googleドキュメント / スライド / スプレッドシート
・Googleドライブ上のPDF / 画像 / Wordファイル
※2026年2月現在の情報です。
STEP 3:質問してみる
では、実際にNotebookLMに質問をしてみましょう。
先程読み込ませた記事の内容について質問します。
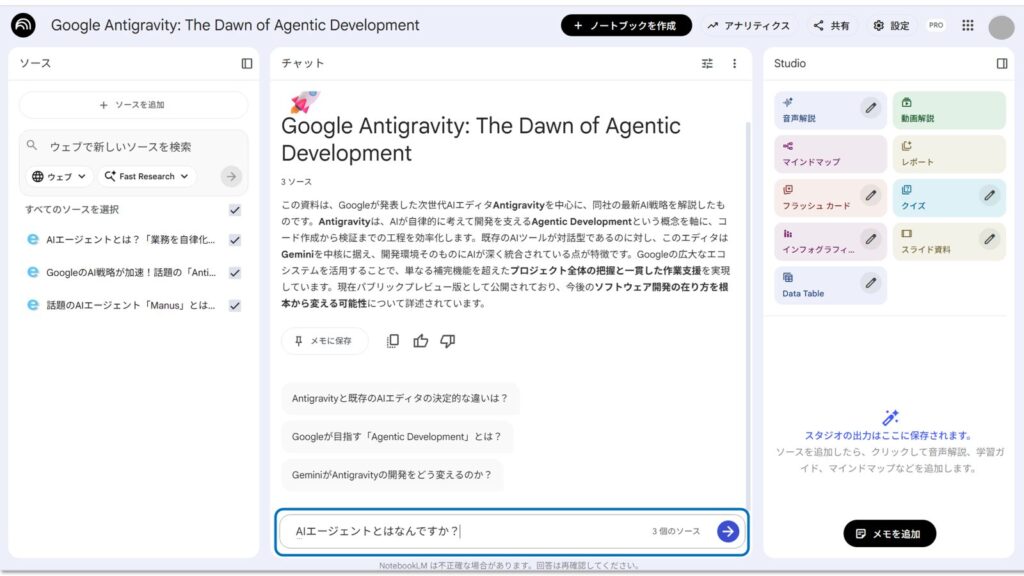
中央下のチャット欄に質問を入力し、エンターで確定します。
すぐに回答が返ってきました。
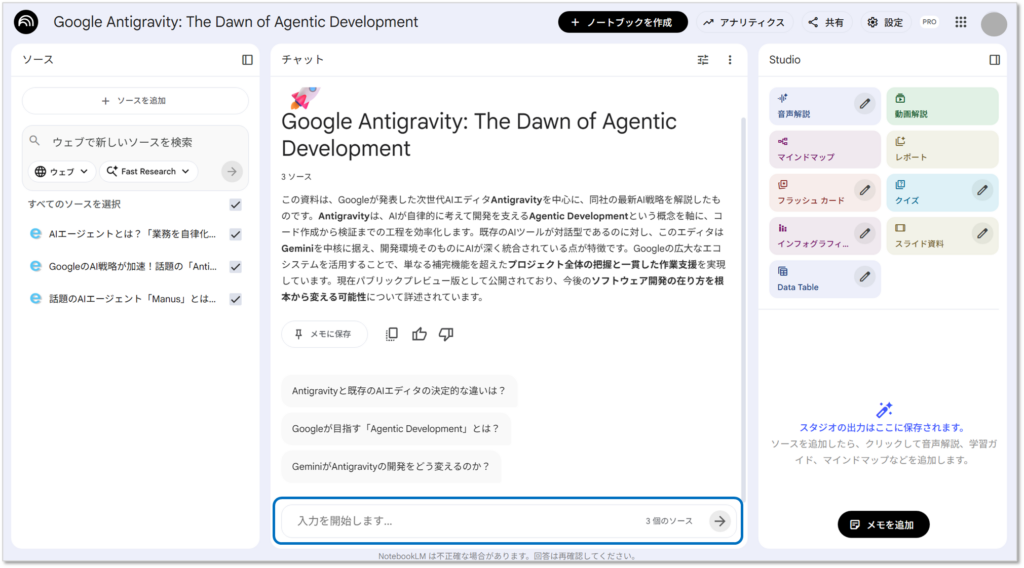
先程データソースとして読み込ませた記事(資料)のみを根拠にした回答が返ってきました。
生成された回答内に表示されている数字部分にカーソルをあてると、参照元の記述がハイライトされます。
たったこれだけの操作でRAGシステムの完成です。
プログラミングも難しい設定も一切不要。
これがNotebookLMの凄さと、注目されている理由です。
本記事では当メディアで公開している情報を提供しましたが、同じ登録手順で社内資料やマニュアルなどを読み込んで試してみてください。
まとめ
「生成AI」と「RAG」。
似ているようで、その役割は大きく異なります。
膨大な知識から新しいものを創り出す「生成AI」と、指定された資料に基づいて正確に回答する「RAG」。
どちらが優れているという話ではなく、適材適所で使い分けることが重要です。
企業の実務において「確実性」を重視する場面では、RAGという選択肢が強力な味方になります。
これまで多大なコストが必要だったこの技術が、NotebookLMのおかげで誰でも手元で試せる時代になりました。
まずは、お手元の「社内マニュアル」や「過去の議事録」を1つ、NotebookLMに入れてみてください。
仕事に活用できそうな手応えを感じることが、DXの大きな第一歩につながるはずです。
\ AI導入・活用でお悩みの中小企業の方へ /
「AI導入したいけど、何から始めればいいの?」「最適なツールや活用法がわからない…」
そんなお悩みはありませんか?
ePla運営会社では、中小企業の業務に合ったAIツールの導入方・活用方法について
無料でご相談を承っています。
導入前に気軽に話せる相談窓口として、ぜひご活用ください。








